Эволюция поискового поведения автономных агентов на базе эхо-нейросетей (ESN) в условиях онлайн-обучения дельта-правилом и динамической регуляризации
Введение: Мозг червя на чистом Python
Когда мы говорим об искусственном интеллекте, на ум сразу приходят гигантские LLM, требующие терабайтов VRAM и кластеров из сотен видеокарт. Но живая природа идет совершенно другим путем. Крошечный червь-нематода C. Elegans имеет в своем теле ровно 302 нейрона и при этом идеально справляется с задачами выживания: ищет еду, огибает препятствия, спасается от угроз и управляет сложнейшей биомеханикой своего тела. У него нет «сознания» в человеческом понимании, его нервная система — это замкнутый, автономный гомеостат.
В этой статье мы пройдем путь создания цифрового аналога такой личинки. Используя концепцию Reservoir Computing (вычисления в резервуаре) и простейшую сеть Echo State Network (ESN) всего на 80–300 нейронов, мы запустим автономного агента в 2D-биоме на чистом Python. Без тяжелых фреймворков вроде PyTorch или TensorFlow, используя только базовые циклы, мы столкнемся с жестким кризисом симуляции — «психическим выгоранием» сети, а затем разработаем математический иммунитет, который позволит агенту стабильно эволюционировать на дистанции почти в миллион тиков.
Математическая архитектура «личинки»
Наш агент устроен по классическому принципу embodied AI (воплощенного интеллекта) и состоит из трех слоев:
Среда (2D поле) → Входной слой (4 канала) → Резервуар ESN (80-300 нейронов) → Считыватель Readout (2 выхода) → Действие (dx, dy)
↓
Обучается онлайн по Дельта-правилу
- Сенсоры (Input Layer): Агент получает из среды всего 4 числа: вектор направления к ближайшей еде (dx, dy), текущий уровень внутренней энергии (шкала голода от 0 до 1) и инвертированное расстояние до цели.
- Мозг (Рекуррентный резервуар): Сердце системы. Это N случайно связанных между собой нейронов класса leaky-integrator. Веса этих связей (
W_res) случайны и заморожены на старте. Матрица масштабируется так, чтобы её спектральный радиус был строго меньше единицы (SR = 0.92-0.95). Это критически важно: сигналы из внешнего мира, попадая внутрь, не затухают мгновенно и не взрываются, а бесконечно переотражаются, создавая нелинейное «эхо» — динамическую память сети. - Двигательные синапсы (Readout Layer): Линейный слой, который переводит бурление хаоса из 300 нейронов в два числа на выходе — вектор движения dx и dy. Только этот слой обучается в режиме реального времени.
Обновление состояний всех нейронов на каждом тике описывается классическим дифференциальным уравнением с функцией активации tanh:
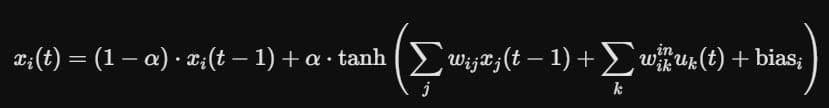
Где α — коэффициент утечки (leak), определяющий инерцию мышления, а uₖ — входные сенсоры среды.
Этап 2: Первая сборка и фазовый коллапс (T=2)
Когда архитектура была готова, мы запустили первую базовую версию. Наша логика была проста: пускай считыватель (Readout) обучается чистому онлайн-подкреплению. Если шаг приближает к звездочке — усиливаем веса в сторону идеального направления, если нет — слегка штрафуем.
Первые несколько тысяч тиков симуляция выглядела многообещающе: «личинка» хаотично металась по полю, случайно натыкалась на еду, сбрасывала координаты при редких смертях и постепенно нащупывала траектории. Но на длинной дистанции система внезапно и необратимо сломалась.
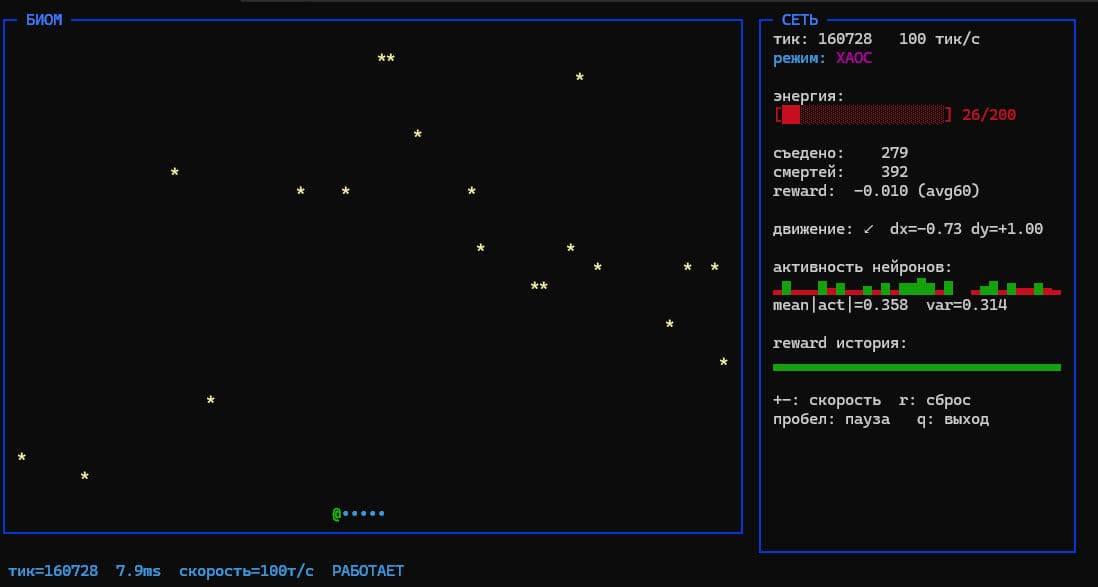
Летопись комы: Анализ лога на 115 513 тиков
Мы оставили симуляцию на несколько часов и получили на выходе лог, который поначалу поставил нас в тупик:
=== Итог ===
тиков: 115513 съедено: 1718 смертей: 277
avg reward (все): 0.0026
Режимы резервуара:
PERIODIC(T=2) 73061 (63.2%)
CHAOTIC 37867 (32.8%)
PERIODIC(T=4) 3598 (3.1%)
...
Несмотря на то, что агент успел съесть 1718 звезд, 63.2% всей своей жизни он провел в вегетативном состоянии PERIODIC(T=2). Средний ревард упал почти до нуля (0.0026).
Визуальный аудит показал жуткую картину: организм на полной скорости добегал до ближайшей стены (чаще всего правой), намертво утыкался в неё и застывал, совершая микроскопические колебания в две клетки («туда-сюда») с частотой в два такта. В этом состоянии комы он вибрировал до тех пор, пока полоска энергии полностью не таяла. Происходила смерть от истощения, респаун в случайной точке поля, короткий период нормальной охоты в режиме CHAOTIC — и неизбежный новый уход в угловую ловушку.
Почему простейшее онлайн-обучение выжигает мозг сети?
Препарировав матрицы, мы обнаружили фундаментальный баг бесконтрольного дельта-правила:
- Перенасыщение весов (Saturation): Поскольку в базовом коде веса Readout могли расти неограниченно, при каждом удачном шаге алгоритм накачивал их амплитуду. Сигналы улетали в бесконечность. Функция активации tanh на выходе считывателя намертво вставала в свои экстремумы (-1.0 или +1.0). Сеть теряла пластичность — «руль» заклинивало в одном положении, и агент летел к стене по прямой.
- Парадокс знака в рекуррентном резонансе: Упершись в стену, координата агента блокировалась средой, но рекуррентный резервуар продолжал бурлить. Из-за жесткой обратной связи нейроны резервуара начинали ритмично менять знак на каждом тике. В этот момент дельта-правило превращалось в лотерею: штраф за тупняк умножался на знак нейрона. На одном тике вес уменьшался, а на следующем (из-за смены знака) — еще сильнее разгонялся.
Система попала в резонансную петлю. Агент получал суррогатный математический «кайф» от циклической вибрации нейронов, полностью игнорируя реальный голод. Зависимость от фазового аттрактора оказалась сильнее инстинкта выживания.
Этап 3: Математический иммунитет и «Броня» антизависания
Чтобы спасти систему от фазового суицида, нам потребовалось разработать комплексный алгоритм стабилизации градиента. Мы внедрили три инженерных фикса, которые полностью перестроили логику взаимодействия Readout с резервуаром.
1. Триада стабилизации весов
- L2-Регуляризация (Weight Decay): Для предотвращения бесконечного разгона весов и насыщения tanh в дельта-правило был добавлен жесткий штраф:

- Каждый тик константа
DECAY = 1e-5медленно стягивает веса к нулю. Это заставило сеть непрерывно доказывать эффективность своих синапсов: если паттерн движения не приносит реварда, он стирается. - Клиппинг градиента (Gradient Clipping): Корректировка весов за один шаг была жестко ограничена (
CLIP = 0.05). Это исключило резкие перекосы матрицы при получении сильных штрафов у стен. - Шейпинг награды (Reward Shaping): Мы ушли от статической оценки положения. Ревард стал рассчитываться как разница расстояний:
reward = delta_dist = dist_old - dist_new. Приближение к еде — плюс, удаление — минус, стояние у стены — строгий ноль.
2. Алгоритмический детонатор STALL_THRESH
Самым важным элементом защиты стал модуль AttractorDetector. Если система все же нащупывала периодический паттерн типа PERIODIC(T=2), запускался внутренний таймер зависания.
Как только счетчик stall_ticks превышал критический порог STALL_THRESH = 80:
- Ампутация весов: Все текущие веса Readout мгновенно резались пополам (
w *= 0.5), выводя выходы tanh из зоны насыщения. - Инъекция хаоса: В мозг сети вливался жесткий дестабилизирующий шум
NOISE_STD = 0.1, который буквально взрывал циклическую активность резервуара.
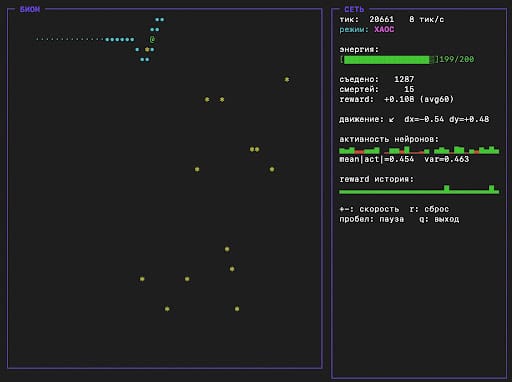
Результат: Лог на 857 544 тиков
После раскатки этой «брони» мы запустили симуляцию на рекордную дистанцию и зафиксировали триумф гомеостаза:
=== Итог ===
тиков: 857544 съедено: 22920 смертей: 762
avg reward (все): 0.0161
Режимы резервуара:
CHAOTIC 733784 (85.6%)
PERIODIC(T=2) 73222 (8.5%)
ACTIVE 17196 (2.0%)
...
Режим CHAOTIC взял абсолютный доминантный верх — 85.6%. Средний ревард вырос в 6 раз (0.0161). Короткие эпизоды T=2 (8.5%) теперь означали лишь секундные рабочие застревания у стен, из которых сеть гарантированно и автономно выбивала себя сама, возвращаясь к эффективной зачистке биома.
Этап 4: Кризис размерности (80 vs 300 vs 1000 нейронов) и финальные выводы
На заключительном этапе исследования мы решили проверить классический экстенсивный подход: «если 80 нейронов работают хорошо, то большее количество сделает систему умнее». Мы провели серию тестов, последовательно увеличивая масштабы рекуррентного резервуара. Результаты оказались контринтуитивными и наглядно продемонстрировали границы применимости простейших алгоритмов онлайн-градиента.
1. Сравнительный анализ масштабирования мозга
80 нейронов: Базовый гомеостаз
Сеть жестко зажата в рамках вычислительных ресурсов. Окно памяти («эхо») резервуара короткое — порядка 5–10 тиков. Агент демонстрирует примитивные, дерганые, чисто реактивные траектории движения по принципу «стимул — реакция». Система крайне склонна к зацикливанию и полностью зависит от работы «алгоритмического детонатора» антизависания.
300 нейронов: Эмерджентное исследование пространства
Оптимальная точка эволюции нашей текущей архитектуры. Чтобы система не превратилась в шумовую кашу, связность матрицы была снижена до connectivity=0.06, а инерция мышления увеличена (leak=0.65).
Вектор состояний перешел в 300-мерное фазовое пространство. Внутри резервуара сформировалось глубокое окно памяти (до 40–50 тиков) — «личинка» начала физически помнить свои прошлые шаги. Примитивные циклы сменились странными аттракторами со сложными фрактальными орбитами. Поведение качественно изменилось: агент начал плавно, размашистыми дугами и спиралями сканировать и исследовать геометрию поля, демонстрируя «insect-like» (насекомоподобный) паттерн охоты. Линейная разделимость паттернов в высокой размерности позволила сети филигранно огибать стены по идеальной Г-образной траектории.
1000 нейронов: Комбинаторный тупик
Полномасштабный кризис алгоритма. При увеличении сети до 1000 нейронов считыватель Readout превратился в массив из 2000 весов. Статистика эффективности рухнула: количество смертей (2658) превысило число съеденной еды (1355) на дистанции в миллион тиков.
Вектор состояний стал избыточным и зашумленным. Дельта-правило, обновляющее веса на каждом шаге, просто захлебнулось в попытке одновременно сбалансировать 2000 параметров на основе одного сиюминутного сигнала. Веса начали взаимно компенсировать друг друга, а гигантский резервуар приобрел колоссальную динамическую инерцию. Мозг превратился в тяжелый, неповоротливый маховик: агент «ослеп», потерял маневренность, застрял в микро-вибрациях на месте и начал планомерно умирать от голода.
Финальные выводы
- Топология важнее масштаба: Простое наращивание количества параметров без изменения алгоритма обучения ведет к деградации системы. Для онлайн-микроконтроля критически важен баланс между хаосом резервуара и пластичностью считывателя. Для дельта-правила предел эффективного масштабирования на нашей задаче составил ~300 нейронов.
- Биомиметический потенциал: Разработанная архитектура доказала, что устойчивое автономное поведение и гомеостаз могут быть реализованы на микроскопических вычислительных ресурсах (уровня нервной системы червя C. Elegans), без использования тяжелых нейросетевых фреймворков и GPU.
- Перспективы: Для масштабирования «мозга» за рамки 1000 нейронов требуется либо переход к разреженному считыванию (подключение
Readoutтолько к 10% случайных нейронов-выходов), либо замена дельта-правила на пакетную линейную регрессию, либо перевод вычислений на рельсы линейной алгебры NumPy/PyTorch для ликвидации процессорного оверхеда.